Choosing the Right Data Structure for Real-World Problems
Have you ever asked yourself which data structure you should use to store your collection of items? It’s a common question every Java developer faces, especially when writing scalable and maintainable code.
Java’s Collections Framework offers a variety of implementations for lists, sets, and maps—but using the right one in the right context can make a big difference in performance, readability, and correctness.
This post explores six commonly used collection types: 👉 ArrayList, LinkedList, HashSet, TreeSet, HashMap, and TreeMap And it gives real-world examples where each shines, so you can think critically about which one fits your situation best.
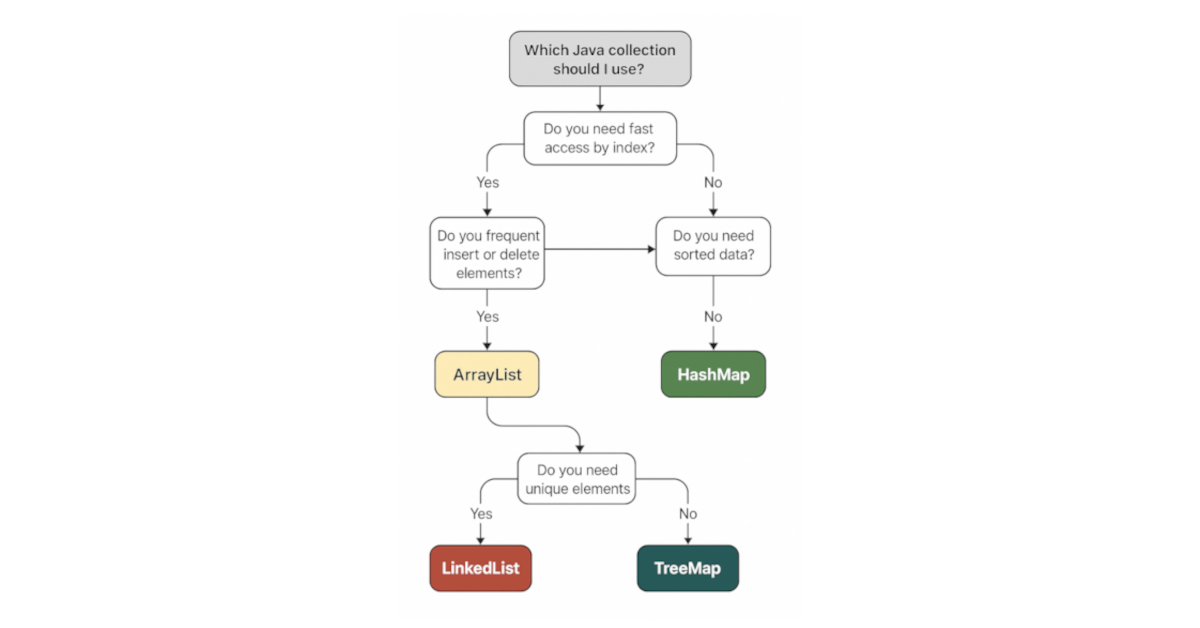
✅ ArrayList – When Fast Access Matters
Real-World Problem: You’re building a search suggestion dropdown that displays a list of recently typed queries.
Why it fits: ArrayList gives constant-time access by index. You can instantly show the N-th recent search. Since you’re only adding at the end or reading in order, it’s perfect.
Avoid if: You’re doing lots of insertions or deletions in the middle of the list.
🔁 LinkedList – When Frequent Insertions or Deletions Are Needed
Real-World Problem: You’re building a playlist feature where users can frequently rearrange songs (move up/down), insert between, or remove them.
Why it fits: LinkedList is a doubly-linked list. It handles frequent adds/removals from anywhere in the list faster than an ArrayList, especially for large lists.
Avoid if: You need random access to elements; get(index) is slow.
🧺 HashSet – When Uniqueness Is the Only Requirement
Real-World Problem: You’re storing a list of all email addresses that signed up for a beta program, and duplicates must be prevented.
Why it fits: HashSet automatically ensures uniqueness and gives constant-time add, remove, and contains operations. Perfect for preventing duplicate entries.
Avoid if: You care about insertion order or need sorted output.
🌲 TreeSet – When You Need Sorted, Unique Data
Real-World Problem: You’re storing a leaderboard with player scores and want to keep them in ascending or descending order, without duplicates.
Why it fits: TreeSet keeps elements sorted according to their natural order (or a custom comparator) and ensures uniqueness.
Avoid if: You don’t need sorting—HashSet is faster.
🗂️ HashMap – When You Need Key-Based Fast Lookup
Real-World Problem: You’re building a dictionary app where users type a word and you fetch its definition instantly.
Why it fits: HashMap offers constant-time retrieval for keys. It’s ideal for any key-value lookup scenario, like config values, routing tables, or caching.
Avoid if: You need sorted keys or order-sensitive operations.
🧭 TreeMap – When You Need Sorted Keys
Real-World Problem: You’re storing time-series sensor data where each data point has a timestamp as the key, and you want to retrieve them in chronological order.
Why it fits: TreeMapkeeps keys sorted, making it perfect for time-based logs, ranges, or navigation systems.
Avoid if: Key order doesn’t matter—HashMap is more performant.
📚 Code Examples + Performance Overview
We’ll now walk through each collection with:
🔧 A practical Java code example
⚙️ Performance notes for common operations
✅ ArrayList – Fast Access, Ordered Collection
List<String> recentSearches = new ArrayList<>();
recentSearches.add("Java Streams");
recentSearches.add("Spring Boot");
recentSearches.add("Docker");
// Fast access by index
System.out.println(recentSearches.get(1)); // Output: Spring Boot
✅ Use for: sorted data, range queries ⚠️ Avoid for: high-volume add/remove where sorting isn’t needed
🗂️ HashMap – Key-Based Lookup (Unordered)
Map<String, String> dictionary = new HashMap<>();
dictionary.put("Java", "A programming language");
dictionary.put("Spring", "A Java framework");
System.out.println(dictionary.get("Java")); // A programming language
⚙️ Performance
Operation
Complexity
put()
O(1)
get(key)
O(1)
remove()
O(1)
✅ Use for: fast lookups, caching, config storage ⚠️ Avoid for: sorted or ordered key access
✅ Use for: sorted maps, time-series, navigation by key ⚠️ Avoid for: massive inserts where sorting isn’t needed
ArrayList or TreeMap?
✅ Use ArrayList + Collections.sort() if:
You add many elements quickly, then sort once before accessing them.
You don’t need automatic sorting after each insert.
You can tolerate O(n log n) cost only when needed.
List<Integer> list = new ArrayList<>();
list.add(5);
list.add(1);
list.add(3);
Collections.sort(list); // O(n log n) when you want sorting
Pros:
Faster inserts (O(1) per element).
More efficient if sorting is infrequent.
Cons:
Data is not always sorted.
Sorting must be manually triggered.
✅ Use TreeMap (or TreeSet) if:
You need elements always kept in sorted order.
You frequently add, remove, and retrieve items in sorted order.
Sorted access (e.g., range queries or iteration in order) is frequent.
Map<Integer, String> sortedMap = new TreeMap<>();
sortedMap.put(5, "five");
sortedMap.put(1, "one");
sortedMap.put(3, "three");
// Always sorted by keys
Pros:
Automatically sorted.
Great for range-based access, floor/ceiling queries.
Cons:
Slower insertions (O(log n)).
Slightly higher memory overhead.
🔍 Summary Table
Feature
ArrayList + sort()
TreeMap
Insert performance
O(1)
O(log n)
Maintain sorted order
❌ (manual sort)
✅ (always sorted by key)
Sorted iteration
After sort only
Always sorted
Use case
Batch sort, occasional order
Continuous ordered access
💡 Choose TreeMap if sorting is a core requirement throughout the lifecycle. Choose ArrayList + sort() if you’re optimizing for bulk inserts followed by occasional sorting.
Summary of all java collections
Collection
Type
Implements
Main Purpose
Key Characteristics
ArrayList
List
RandomAccess, List
Dynamic array for fast access and iteration
Fast random access, slow inserts/removals in the middle, ordered, allows duplicates
LinkedList
List
Deque, List
Doubly-linked list for efficient insertion/deletion
Slower access time than ArrayList, fast inserts/removals, ordered, allows duplicates
Vector
List
RandomAccess, List
Thread-safe dynamic array (legacy)
Synchronized, slower than ArrayList in single-threaded contexts
Stack
List
Vector (extends)
LIFO stack implementation
Thread-safe, legacy class, now replaced by Deque
HashSet
Set
Set
Store unique elements with no order
Backed by HashMap, no duplicates, fast lookup
LinkedHashSet
Set
Set
Store unique elements maintaining insertion order
Preserves insertion order, slightly slower than HashSet
TreeSet
Set
NavigableSet
Store sorted unique elements
Sorted order (natural or custom), slower than HashSet, no duplicates
PriorityQueue
Queue
Queue
Queue elements with priority (min-heap by default)
Elements ordered by priority, not thread-safe
ArrayDeque
Queue
Deque
Resizable array for double-ended queue (stack or queue)
Faster than Stack or LinkedList for stack/queue operations
HashMap
Map
Map
Store key-value pairs with no specific order
Allows one null key, fast lookup, not synchronized
LinkedHashMap
Map
Map
Key-value pairs maintaining insertion order
Predictable iteration order, slightly slower than HashMap
TreeMap
Map
NavigableMap
Sorted map based on keys
Sorted by natural or custom comparator, slower than HashMap
Hashtable
Map
Map
Thread-safe key-value store (legacy)
Synchronized, slower, no null keys or values
ConcurrentHashMap
Map
ConcurrentMap
Thread-safe, high-performance concurrent map
Allows concurrent reads and controlled writes, no null keys/values
EnumSet
Set
Set
Specialized set for use with enum types
Fast and compact, only works with enums
EnumMap
Map
Map
Specialized map for enum keys
Efficient and compact, only works with enum keys
WeakHashMap
Map
Map
Map with weak keys for memory-sensitive caching
Keys are GC’d when no longer referenced, good for caches
IdentityHashMap
Map
Map
Map that uses == instead of .equals() for comparing keys
Not commonly used, but useful in specific identity-based contexts